How to Use BibCrit
BibCrit is a Claude-powered biblical textual criticism toolkit. Each tool streams AI analysis directly in your browser, letting you explore divergences between the Masoretic Text (MT) and the Septuagint (LXX), profile scribal tendencies, model numerical discrepancies, reconstruct plausible Hebrew Vorlagen, compare Dead Sea Scrolls witnesses, trace patristic citations, detect theological revisions, visualize manuscript transmission, compare Targum Onkelos and Jonathan renderings, analyze NT textual traditions and variant registers, map chiastic structures, and analyze source layers — all without installing any software.
Analysis Tools
find_in_pageMT/LXX Divergence Analyzer
Enter a verse or chapter reference and BibCrit lists every word-level divergence between the Hebrew MT and the Greek LXX, classifying each as a translation technique, inner-Greek variant, or evidence for a divergent Vorlage. Results stream in real time via Server-Sent Events.
Try Psalm 22:1 →translateBack-Translation Workbench
For any LXX passage, Claude reconstructs the most probable Hebrew text that would have generated the Greek, annotating each back-translated word with its confidence level and the translation strategy it implies. Ideal for identifying passages where the LXX preserves a textual variant invisible in the MT.
Try Exodus 3:14 →radarScribal Tendency Profiler
Select an LXX book and get a five-axis radar chart of the translator's characteristic tendencies: literalness, anthropomorphism reduction, messianic heightening, harmonization with other biblical books, and overall paraphrase rate. Each dimension is scored and supported by real textual examples.
Try Isaiah →calculateNumerical Discrepancy Modeler
Genealogical ages, census figures, and chronological numbers routinely differ between MT, LXX, and SP. Enter a reference (e.g. Genesis 5) and Claude models which tradition preserves the earlier tradition, what scribal mechanism likely caused the shift, and how each manuscript family resolves the arithmetic.
Try Genesis 5 →history_eduAncient Witness Bridge
Compare a biblical passage across five ancient witnesses simultaneously: Dead Sea Scrolls, Samaritan Pentateuch, Peshitta (Syriac OT), Masoretic Text, and Septuagint. See which traditions attest the passage, how each aligns, and the specific divergences — bringing the earliest surviving manuscripts into your analysis.
Try Isaiah 7:14 →psychologyTheological Revision Detector
Identify where translators or scribes may have altered the text for theological reasons — anthropomorphism avoidance, messianic heightening, polemical changes, or harmonization with theological conventions. Each flagged passage is assessed for its likely motivation and tradent context.
Try Genesis 1:1 →churchPatristic Citation Tracker
Trace how Church Fathers through the 5th century cited a biblical passage, what text form they used (MT-like, LXX-like, or divergent), and what their citations reveal about early textual transmission. Patristic evidence often preserves readings lost from surviving manuscript branches.
Try Isaiah 53:1 →menu_bookNT Use of OT Analyzer
Enter a New Testament passage and identify every Old Testament allusion it contains. For each allusion, the tool determines whether the NT author was citing the Hebrew text (MT), the Greek translation (LXX), an independent form, or a conflation — applying the methodology of Beale & Carson, Stanley, and Hays.
Try Romans 15:12 →account_treeManuscript Transmission
See how a biblical book's text was transmitted — from proto-text through the major traditions (MT, LXX, DSS, SP, Peshitta, Targum, Vulgate) to modern critical editions. A schematic overview of how the traditions relate and where they diverge — an orientation diagram, not a stemma reconstructed from collation.
Try Isaiah →swap_vertChiasm Detector
Detect concentric (chiastic) literary structures in any biblical passage. The tool identifies labeled structural units (A–B–C–X–C′–B′–A′), annotates the pivot/climax, maps correspondences between parallel panels, and assesses overall structural integrity. Results include a full diagram, confidence score, and a BibCrit hypothesis on theological significance.
Try Amos 5:1–17 →layersSource Criticism
Analyze a passage for documentary source layers using classical criteria: divine name usage (YHWH vs. Elohim), vocabulary patterns, doublets, theological concerns, and narrative tensions. Each identified unit is assigned a traditional source designation (J, E, D, P, or Redactor) with confidence level, supporting evidence, and scholarly debate context.
Try Genesis 1–2 →auto_storiesTargum Comparator
Compare any Torah or Prophets passage against Targum Onkelos (Torah) or Targum Jonathan (Prophets) alongside the Hebrew MT and Greek LXX. The tool identifies Memra substitutions for the divine name, anthropomorphism softening, targumic expansions with Midrashic parallels, and messianic reinterpretations absent from the MT. Targum text is displayed in Hebrew square script — the same alphabet as Biblical Hebrew, though the language is Jewish Aramaic.
Try Genesis 22:8 →fact_checkNT Textual Tradition Analyzer
For any New Testament passage, identifies its textual stability across the four major manuscript families — Alexandrian (P66, P75, Sinaiticus, Vaticanus), Western (Bezae, Old Latin), Byzantine (Majority Text), and Caesarean (P45, family 1, family 13) — and assigns a Metzger A/B/C/D confidence rating. Includes extended analysis for the six major disputed passages: Mark 16:9–20, John 7:53–8:11, Luke 22:43–44, 1 John 5:7–8, Acts 8:37, and Romans 16:25–27.
Try Mark 16:9 →temple_hinduSecond Temple Literature Bridge
Map allusions and parallels between any canonical passage and five major Second Temple works: 1 Enoch, Jubilees, Sirach (Ben Sira), 4 Ezra, and Tobit. Each allusion is classified by type (citation, allusion, echo, parallel), directionality (whether the STL text depends on the canonical text or vice versa), and confidence, applying the methodology of Nickelsburg, VanderKam, Collins, Knibb, and Hays.
Try Genesis 6:1–4 — Sons of God / Nephilim →Manuscript Traditions
BibCrit works across seven major textual witnesses to the Hebrew Bible and New Testament, each with its own transmission history and scholarly edition.
| Tradition | Full name | Language | Approximate date | Standard edition |
|---|---|---|---|---|
| MT | Masoretic Text | Biblical Hebrew / Aramaic | Consonantal text c. 1st c. BCE; Tiberian vocalization c. 7th–10th c. CE | Biblia Hebraica Stuttgartensia / BHQ |
| LXX | Septuagint | Koine Greek | 3rd–1st c. BCE (Pentateuch earliest) | Göttingen Septuagint (critical); Rahlfs-Hanhart (hand edition) |
| SP | Samaritan Pentateuch | Samaritan Hebrew | Script diverges c. 6th–4th c. BCE; extant MSS medieval | von Gall 1918; HBCE (in progress) |
| DSS | Dead Sea Scrolls | Hebrew / Aramaic | c. 250 BCE – 68 CE (Qumran deposits) | DJD series (Oxford); Leon Levy DSS Digital Library |
| PESH | Peshitta | Classical Syriac | OT books translated c. 1st–2nd c. CE | Leiden Peshitta (Brill); CAL (Comprehensive Aramaic Lexicon) |
| TARG | Targum Onkelos (Torah) / Targum Jonathan (Prophets) | Jewish Babylonian Aramaic — written in Hebrew square script | Onkelos: redacted c. 2nd–3rd c. CE; Jonathan: redacted c. 4th–5th c. CE | Sperber 1959–1973; Sefaria critical text |
| VUL | Vulgate (Clementine) | Latin | Translated by Jerome c. 382–405 CE; Clementine revision 1592 | Biblia Sacra iuxta Vulgatam Versionem (Weber-Gryson); scrollmapper edition |
How Analysis Works
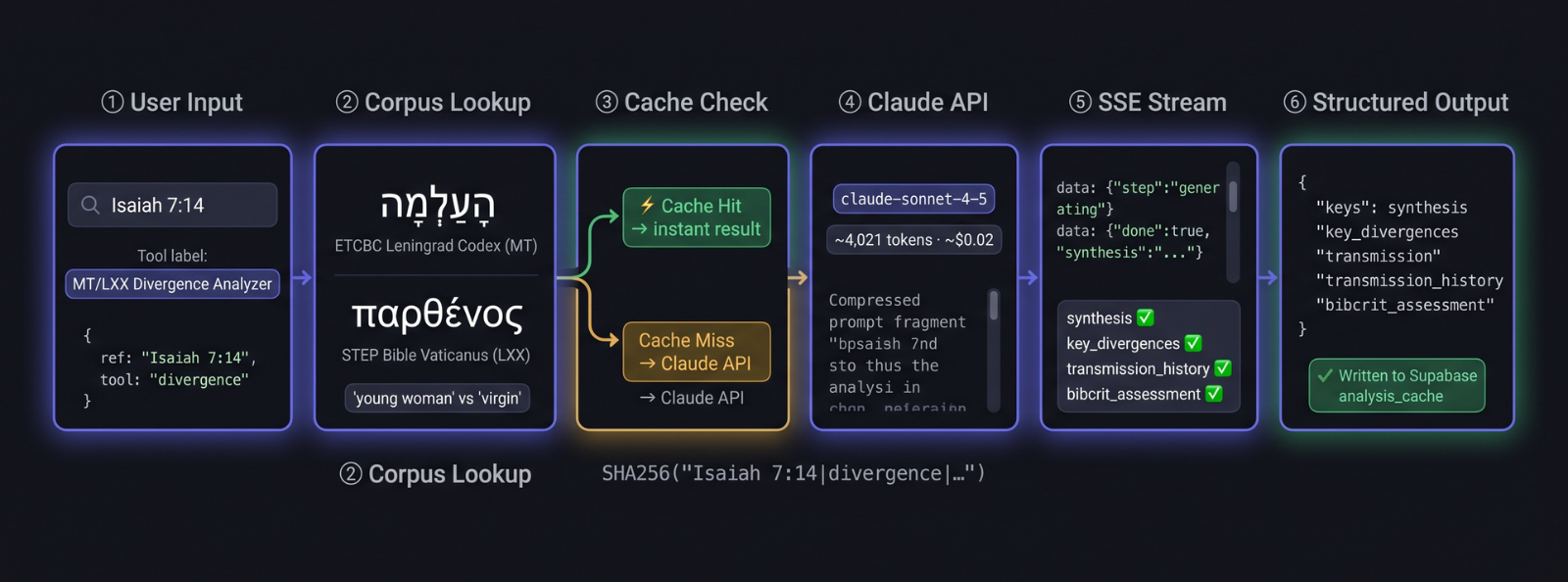
Each BibCrit tool draws on Claude's extensive training in biblical studies, ancient languages, and the primary literature of textual criticism. When you submit a passage or book, Claude consults that training knowledge to apply the same analytical frameworks used in critical scholarship — Tov's divergence taxonomy for the Divergence Analyzer, Aejmelaeus's translation-technique categories for the Scribal Profiler, the standard Vorlage reconstruction methodology for the Back-Translation Workbench, and so on. See Scholarship & Methodology for the specific sources that inform each tool.
Where the analysis touches manuscript data that can be verified — such as the presence of a Dead Sea Scrolls witness, the alignment of a patristic citation, or the numerical value in a specific tradition — Claude cross-checks its response against its knowledge of the standard critical editions. Results stream to your browser in real time so you can follow the analysis as it develops. Frequently analyzed passages load from a shared cache, so you see prior results immediately.
All analysis is produced from Claude's training knowledge. BibCrit does not query external databases at runtime. Results should be cross-checked against primary sources — BHS/BHQ, the Göttingen LXX, the DSS transcriptions — before citation in peer-reviewed work.
Understanding Confidence Scores
Each divergence, back-translation item, or numerical interpretation carries a confidence badge reflecting how well-attested the scholarly judgment is:
The conclusion is strongly supported by textual evidence and documented in major critical commentaries or critical editions. Multiple independent witnesses or well-established translation pattern.
The interpretation is plausible and consistent with known scribal patterns, but alternative explanations exist. Treat as a working hypothesis for further investigation.
The evidence is ambiguous or the judgment involves significant inference. Useful as a starting point but should be checked against primary sources before citation.
Scholarship & Methodology
BibCrit's prompts are informed by the standard reference works and methodological frameworks of LXX and textual criticism scholarship. Key sources include:
- Emanuel Tov — Textual Criticism of the Hebrew Bible (3rd ed., Fortress, 2012): the standard taxonomy of divergence types, Vorlage reconstruction methodology, and scribal error classification.
- Anneli Aejmelaeus — On the Trail of the Septuagint Translators (Peeters, 2007): translation technique analysis, literalness scoring, and paratactic vs. hypotactic syntax tendencies.
- Jan de Waard & Eugene Nida — A Translator's Handbook on the Bible: functional equivalence principles used to classify paraphrase and dynamic rendering.
- Biblia Hebraica Stuttgartensia (BHS) and Biblia Hebraica Quinta (BHQ): the critical apparatus entries that classify variants as Vorlage differences, inner-Greek corruption, or translation choices.
- Göttingen Septuagint: critical edition used for LXX textual variants and Greek manuscript attestation.
- Dead Sea Scrolls (4QSama, 1QIsaa, and others): pre-MT Hebrew witnesses that occasionally support LXX pluses and minuses against the MT.
All analysis is produced by Claude from its training knowledge. BibCrit does not call external databases at runtime. Results should be cross-checked against primary sources for peer-reviewed publication.
Open Data API
All cached analyses are freely accessible via a public REST API under the Apache 2.0 license — query, download, and reuse them in your own research or tools.
Example queries:
# All cached analyses (paginated) GET /api/cache # Filter by tool GET /api/cache?tool=divergence # Filter by tool + passage GET /api/cache?tool=theological&ref=Isaiah+7:14 # Only discovery-ready results GET /api/cache?discovery_ready=true&limit=50&offset=0
Each record includes the full structured JSON as generated by Claude, plus metadata: tool, reference, model_version, cached_at. Supported query parameters: tool, ref (substring match), discovery_ready, limit (max 200), offset.
Full interactive documentation for all 14 analysis endpoints, the corpus browser, export formats, and vote routes is at /api/docs (Swagger UI). The machine-readable OpenAPI 3.0 spec is at /api/v1/openapi.json.
A live usage dashboard shows which passages have been analysed, which tools were used, and activity over time — updated in real time from the cache.
If you use BibCrit data in research, please cite:
Fresco Benaim, J. (2026). BibCrit: AI-assisted biblical textual criticism. doi:10.5281/zenodo.19358424
Data Sources
BibCrit's corpus layer is built on eight open academic datasets supplying word-level text across eight manuscript traditions:
-
ETCBC — Eep Talstra Centre for Bible and Computer (Vrije Universiteit Amsterdam)
Provides the Masoretic Text with full morphological tagging (lemma, part of speech, person/gender/number, clause boundaries) via the BHSA dataset. Also the source for the Dead Sea Scrolls corpus (1QIsaᵃ, 4QSamᵃ, 11QPaleoLev, 4QDeutᵏ) and the Peshitta Syriac OT (all 39 OT books, 308,863 word tokens). Peshitta lexical data derives from the SEDRA database (Beth Mardutho: The Syriac Institute). All three ETCBC modules are accessed via Text-Fabric (Hagen). Licensed CC-BY-NC 4.0.
ETCBC/BHSA on GitHub → -
STEP Bible — Tyndale House, Cambridge
Provides the Septuagint (LXX) text with morphological tagging, Strong's numbers, and manuscript sigla (primarily Vaticanus). Covers the full LXX canon (38 books). BibCrit uses it as its LXX corpus for all Greek-side analysis.
STEPBible-Data on GitHub → -
SBLGNT — Society of Biblical Literature
The SBL Greek New Testament provides the morphologically tagged Greek text for all 27 NT books (137,554 word tokens). Used by the NT Textual Tradition Analyzer and the NT Use of OT Analyzer.
SBLGNT on GitHub → -
Sefaria — Targum Onkelos & Targum Jonathan
Sefaria's openly licensed export provides the Aramaic Targum text for Torah (Onkelos, 5 books) and Prophets (Jonathan, 21 books) — 26 books and 240,297 Aramaic word tokens in total. Note: Targum uses the Hebrew square script, not Syriac. Attributed per Sefaria's CC BY-SA license.
Sefaria-Export on GitHub → -
scrollmapper/bible_databases — Clementine Vulgate
Provides Jerome's Latin Vulgate (Clementine edition, 1592) across the full Protestant canon — 66 books, 569,588 Latin word tokens. Used by the DSS Bridge, Manuscript Transmission, and Theological Revision Detector to add a 4th-century Latin witness to each analysis.
scrollmapper/bible_databases on GitHub → -
Samaritan Pentateuch — dt-ucph/sp (University of Copenhagen)
The Samaritan Pentateuch Text-Fabric module provides the SP text for the five Torah books, used primarily by the Numerical Discrepancy Modeler to compare patriarchal chronologies across MT, LXX, and SP traditions. Accessed via Text-Fabric (Hagen).
dt-ucph/sp on GitHub → -
Patristic sources
The Patristic Citation Tracker uses Claude's knowledge of the standard critical editions (Migne PG/PL, Sources Chrétiennes, ANF/NPNF) to surface how Church Fathers through the 5th century cited biblical passages and what text form their quotations reflect.
All corpus data is used in accordance with the respective open licenses. See the BibCrit repository for full attribution.
Frequently Asked Questions
- Methodology & Scholarly Use
-
Can BibCrit analyses be cited in peer-reviewed publications or dissertations? ▾
With appropriate qualification, yes. BibCrit is a research aid — not a primary source or a peer-reviewed commentary. Its analyses reflect Claude's training on published scholarship (Tov, Ulrich, Kraft, Nickelsburg, VanderKam, Metzger, and others) but have not been independently verified by human specialists.
Recommended citation practice: use BibCrit to identify hypotheses, map the terrain, and generate leads; then verify significant findings against the primary critical editions (BHS/BHQ, Göttingen LXX, DJD series) and the specialist literature BibCrit cites. When you do cite BibCrit directly, use the DOI: 10.5281/zenodo.19358424.
-
How should confidence scores be interpreted? ▾
Confidence scores (0.0–1.0) reflect the model's assessment of scholarly consensus strength for a given classification — not a probability derived from Bayesian inference or a corpus frequency count. A score of 0.85 means the model judges the classification to be well-supported by mainstream critical scholarship; 0.55 indicates genuine scholarly debate or ambiguous evidence.
The scores are calibrated against the stated methodology for each tool (e.g. Tov's divergence typology for the Divergence Analyzer, Hays' six criteria for the STL Bridge). They should be read as a proxy for scholarly consensus density, not as a statistical confidence interval. Always consult the scholarly_note fields for the underlying reasoning.
-
How does BibCrit distinguish a different Vorlage from inner-Greek or scribal variation? ▾
The Divergence Analyzer applies Tov's four-category typology: (1) different Vorlage — the LXX translator had a Hebrew text that already differed from proto-MT; (2) inner-Greek transmission error — the difference arose in the Greek manuscript chain after translation; (3) translator technique — a deliberate rendering decision by the translator (e.g. theological tendency, lexical substitution); (4) scribal error in either tradition. The Back-Translation Workbench separately attempts to reconstruct the Hebrew that would have produced a given Greek reading, then evaluates whether that Hebrew is attested in DSS or SP.
The model's typology classification is always provisional. For high-stakes divergences (e.g. Isaiah 7:14, Deuteronomy 32:8, Psalm 22:17), the scholarly debate is centuries old and BibCrit surfaces the leading positions without adjudicating them definitively.
-
How are Hays' criteria applied in the Second Temple Literature Bridge? ▾
Each allusion in the STL Bridge is evaluated against Hays' six criteria from Echoes of Scripture in the Letters of Paul (1989): availability (was the source text accessible to the author?), volume (how extensive is the verbal/thematic overlap?), recurrence (does the author echo this source elsewhere?), thematic coherence (does the echo fit the surrounding argument?), historical plausibility (is this connection plausible within the author's social/historical context?), and satisfaction (does the allusion enrich the reading?). The confidence score aggregates across all six criteria, weighted by the primary methodology of Nickelsburg, VanderKam, Collins, or Knibb depending on the work being assessed.
-
Are analyses deterministic? Will the same passage always return the same result? ▾
Once cached, yes — every subsequent request for the same passage and tool returns the identical JSON from the cache (Supabase + local disk). Cache keys are
SHA256(reference|tool|prompt_version|model_version), so results are stable until a prompt or model version changes.The first generation of any passage is stochastic (LLM sampling). If you need reproducibility for a specific result, note the
model_versionandprompt_versionfields returned in the response. If a prompt version is incremented (e.g.divergence_v3), all existing cache entries for that tool are invalidated and regenerated on next request. -
How does BibCrit handle passages where the scholarly consensus is genuinely divided? ▾
Contested passages receive multi-hypothesis treatment. Rather than committing to a single classification, the model returns competing hypotheses each with a confidence weight and a scholarly note identifying the principal proponents. Confidence scores on contested readings are typically in the 0.45–0.65 range to signal ambiguity — that range is a feature, not a limitation.
For the most debated passages (Deuteronomy 32:8 MT vs. LXX/DSS; Psalm 22:17 kāʿărî/kārû; Isaiah 53:11), BibCrit surfaces the Barthélemy, Tov, and Ulrich positions rather than arbitrating. The assessment section explicitly names where consensus is weak.
- Corpus & Data
-
Which critical editions back the MT and LXX corpora? ▾
The MT corpus uses the ETCBC BHSA dataset (Biblia Hebraica Stuttgartensia with morphological encoding), the standard computational edition of the Leningrad Codex, distributed via the Text-Fabric framework from the Eep Talstra Centre for Bible and Computer (Vrije Universiteit Amsterdam) under CC BY-NC 4.0. The LXX corpus uses the STEP Bible Rahlfs-Hanhart text with morphological tags, covering 38 books. Neither corpus has been further edited or lemmatized by BibCrit — the word objects are passed to Claude unmodified with reference metadata attached.
-
Which DSS manuscripts are in the corpus? How are lacunae handled? ▾
Four scrolls are loaded: 1QIsaᵃ (Isaiah 1–66, ~95% preserved), 4QSamᵃ (Samuel fragments), 11QPaleoLev (Leviticus fragments in paleo-Hebrew script), and 4QDeutᵏ (Deuteronomy fragments). All are drawn from the ETCBC DSS Text-Fabric module. Lacunose words are represented as empty strings in the corpus; the model is instructed to treat them as absent evidence rather than positive witness. For 1QpHab, the tool filters for verses tagged
biblical=Trueto isolate scriptural quotations from the pesher commentary. -
Does the STL Bridge use an actual corpus of 1 Enoch, Jubilees, etc.? ▾
No — the STL Bridge is a pure AI tool. There is no CLTK or Open Scriptures corpus loaded for Second Temple literature. The model draws on its training knowledge of the Nickelsburg Hermeneia commentary on 1 Enoch, VanderKam's Jubilees edition, Collins' Apocalyptic Imagination, Knibb's Ethiopic Enoch, and the standard critical editions of Sirach, 4 Ezra, and Tobit. This means allusion identification for very obscure passages is less reliable than for well-studied ones; always verify specific passage references against the primary editions (Knibb 1978, VanderKam 2018 CEJL, Skehan–Di Lella AB Sirach).
- Tools & Workflow
-
What is the difference between the Divergence Analyzer and the Ancient Witness Bridge? ▾
The Divergence Analyzer (/divergence) focuses exclusively on MT vs. LXX, producing a word-level apparatus with divergence classification, back-translation hypothesis, and competing scholarly explanations. It is the primary tool for studying the LXX translation and its Vorlage.
The Ancient Witness Bridge (/dss) is a five-tradition comparison tool: MT, LXX, Dead Sea Scrolls (corpus-backed), Samaritan Pentateuch (corpus-backed), and Peshitta (corpus-backed via ETCBC). It is designed for passages where DSS or SP alignment patterns are the central question — e.g. whether a Qumran scroll supports the LXX against MT, or stands independently.
-
How do I export results for use in Zotero, Endnote, or LaTeX? ▾
Every analysis result includes SBL Footnote and BibTeX export buttons in the toolbar below the results. The Divergence Analyzer additionally offers RIS (Zotero, Endnote, Mendeley) and TEI XML export. The Download button produces a plain-text file with the full structured analysis. All exports are also accessible programmatically via the REST API — e.g.
GET /api/divergence/export/bibtex?ref=Isaiah+7:14. -
Can I access the raw JSON output or integrate BibCrit into a research pipeline? ▾
Yes. The full analysis cache is publicly readable via
GET /api/cache?tool=divergence&ref=Isaiah+7:14. Each record returns the complete structured JSON with all fields, plusmodel_version,prompt_version, andcached_atmetadata. The SSE stream endpoints (/api/{tool}/stream) can be consumed programmatically — they emitsectionevents as each JSON key completes, then a finaldoneevent with the full payload. See docs/api-reference.md for full schema documentation. -
How does the Scholar Rating system work? ▾
The ▲/▼ voting buttons below each result submit anonymous upvotes and downvotes to the BibCrit vote API (
POST /api/vote). Votes are stored per tool + reference and inform the Discovery feed's quality ranking — highly-rated analyses surface more prominently. Your vote is stored inlocalStorageso it persists across sessions on the same device. The system is designed to let the scholarly community surface the most methodologically sound results, not to crowdsource truth — a 0.9 confidence score from Claude with 50 upvotes still requires you to check the primary sources.
travel_exploreExplore the Discovery Feed
Browse plain-language summaries of the most interesting MT/LXX divergences, scribal patterns, and numerical traditions already analyzed — no passage reference needed.
Open Discovery →BibCrit was created by Jossi Fresco
![]() 0009-0000-2026-0836
0009-0000-2026-0836
Cite BibCrit
Fresco Benaim, J. (2026). BibCrit: An AI-Assisted Web Application for Biblical Textual Criticism (v3.2.0). Zenodo.
Turn your phone to watch